做数据库相关的同学,相信近几年一定听过很多新闻,比如蚂蚁OceanBase在TPC-C榜单上拿下第一,阿里云AnalyticDB在TPC-H榜单上拿下第一等。感觉TPC-X就是一个衡量数据库性能的标准,各公司希望在这个公认的平台上去获得一个好"成绩",就像是一个权威认证的证书一样,自家的产品就更好卖。花了一点时间简单看了下TPC的背景,由于我的工作主要是在OLAP方向,就以TPC-DS为例做个介绍。
TPC的起源和发展
TPC的官方网站在这里http://tpc.org,在主页上飘着一行小字:The TPC is a non-profit corporation focused on developing data-centric benchmark standards and disseminating objective, verifyable data to the industry. TPC起到两个作用:1. 创造不错的benchmark,2. 创造一个不错的review流程。好的benchmark就像是好的法律,而好的review流程就像是警察,律师,法官这样的角色。因为不管benchmark的细节做到多么细致,总有些所谓的"灰色地带",而好的review流程就可以比较好地处理这些问题。
在80年代初期,交易的自动化越来越普及,比如ATM机,并逐渐扩展到各种方面比如售货店买东西,加油站加油等,即所谓的OnLine Transaction Processing,OLTP系统开始涌现。此时出现了一些benchmark,比如IBM提出的TP1,Jim Gray等人提出的DebitCredit,而因为缺乏很好的review和发布流程,这会让大家的性能结果可信度较低,往往是一片混乱。最终在1988年,Omri Serlin联合了一些公司成立了TPC,也就是Transaction Processing Performance Council。
随之诞生的就是TPC-A(基于DebitCredit)和TPC-B(基于TP1)benchmark,TPC-B和TPC-A的主要区别在于TPC-B可以看作是TPC-A的batch模式,从端上的用户来看,他执行一些少量简单的交易操作,这是TPC-A,而对于那些卖服务器或者卖数据库的公司来说,衡量系统批量处理交易的能力可能更加重要,这是TPC-B。每一个TPC的结果需要有一份Full Disclosure Report,由审核人员进行review,如果有对公开的结果提出异议,会由Technical Advisory Board进行重新review,最后TPC组织根据他们的报告来判断是否需要移除结果。
TPC组织总是希望可以构建更好的benchmark,workloads会随着应用发展的变化而变化,比如TPC-A和TPC-B已经不再使用,OLTP的标准现在是TPC-C。另外TPC也不再局限于做TP领域的benchmark,对于不同的workloads都有对应的benchmark,比如用于决策支持的TPC-DS。
TPC-DS
首先简单理解下决策支持(decision support)的含义,字面上来看就是在一定的业务场景下帮助做一些决策的系统,在我看来就是和OLAP的概念是可以对应起来的,就是对大规模的数据做一些真实业务场景下的分析查询,根据结果做一些相关业务决策。
最早决策支持的benchmark是1994年出来的TPC-D,但当时的复杂查询经过优化器的不断进化已经变得非常快了,而且数据量比较小。在1999年TPC-H诞生,增加了更大规模数据的测试,以及增加了一些查询,但变化较小。最终TPC-DS作为衡量state-of-the-art的决策支持系统性能的最新benchmark,经历了十多年的发展正式成为TPC家族的一员。
在这里我们可以获取到TPC-DS的说明文档和代码。
背景
TPC-DS会使用一个真实的业务场景,商品零售来测试系统性能。构建了一个大型跨国零售公司的业务模型,包含多家专卖店,同时也在线上销售,包含了库存管理系统和促销系统。业务模型分为以下三个方面
数据模型和数据访问:采用雪花模型,有一系列的事实表和维度表,维度表分为以下几类:static(比如日期维度,不会改变),historical(历史记录保留,时间戳代表是否合法,比如item维度),non-historical(新纪录覆盖历史记录,总是使用最新数据,比如customer维度)。包含7张事实表:store_sales,store_returns,catalog_sales,catalog_returns,web_sales,web_returns,inventory。三种渠道的销售和利润数据,以及跟促销有关的数据,还有17张维度表:store,call_center,catalog_page,web_site,web_page,warehouse,customer,customer_address,customer_demographics,date_dim,household_demographics,item,income_band,promotion,reason,ship_mode,time_dim。测试数据大小包含多种size,1TB,3TB,10TB,30TB,100TB。使用SF(Scale Factor)来控制数据规模。
查询模型:包含了多种查询类型,比如查询模式比较固定的报表类查询,比如ad-hoc查询,比如一些包含多join和聚合运算的复杂查询。分析的数据量大,并且都是在回答真实场景下的商业问题。
数据维护(data maintenance,记作DM):这是TPC-DS v3新增的一个测试。OLAP系统的有效性是由业务数据作为基础的,因此从OLTP系统到OLAP系统的数据导入这一步也是很关键的,阶段性的数据"refresh"是数据仓库不可或缺的部分,加入这一个角度使得TPC-DS benchmark更加全面,公平。过程包括加载数据,同时把数据转化成目标格式,删除过期数据,插入新的事实表数据。即包含常说的ETL中的T(Transformation)和L(Load),不包含E(Extraction),也就是下图中flat files的产生过程忽略。
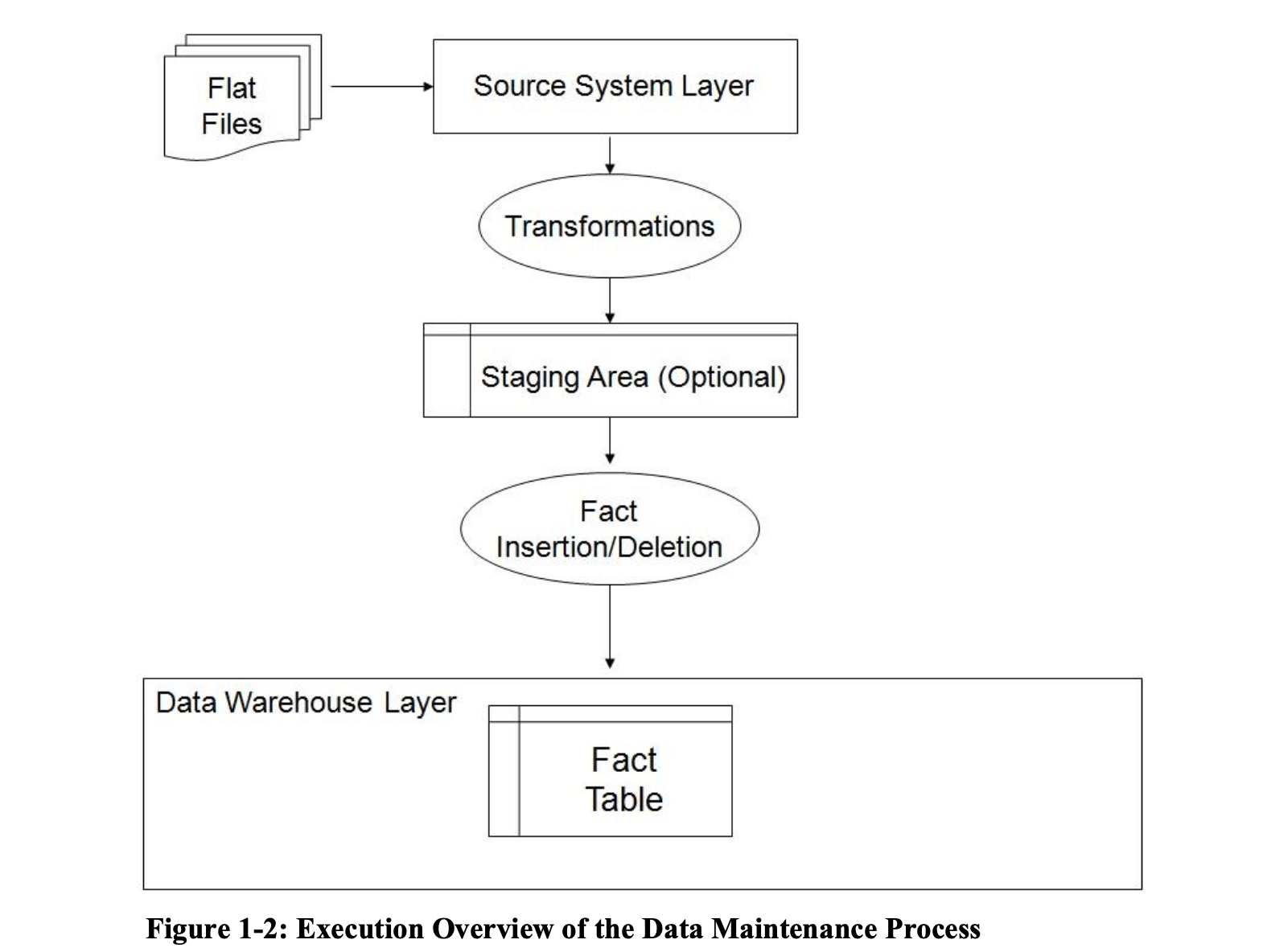
测试
测试分为以下几个流程,有先后顺序
- Load Test
- Power Test
- ThroughPut Test 1
- Data Maintenance Test 1
- Throughput Test 2
- Data Maintenance Test 2
Power test是单线程处理一个query stream(包含99个查询),而Throughput test是并行处S个(TPC-DS要求>=4)query streams,相当于是压测。跑完性能测试以后就开始Data maintenance test做一些数据refresh,替换成新的数据。
测试完成以后,需求有指标来衡量结果。TPC-DS给出了3个主要指标
- Performance Metric,QPhDS@SF
- Price-Performance Metric,$/kQphDS@SF
- System availability date
第一个性能指标直接上原图,SF控制了测试数据规模,Q代表query个数,由于Throughput test会跑几批query streams,总数记为\(S_q\) * 99,于是在\(T_{PT}\)上面我们需要把真实Power test的时间去乘上这个\(S_q\)保证量纲。

第二个价格-性能指标就是计算单位性能指标上的价格,\(\frac{1000 * p}{QphDS@SF}\)。
第三个即为系统开放的可用时间。
报告
最终需要提交一份Full Disclosure Report(FDR),包含以下内容
- Report:完整环境搭建,测试结果等。
- Executive Summary:包含Load Test,Power Test,Throughput Test,Data Maintenance Test的结果,其实Report也包含这部分,单独把这个拎出来作为一个单独文件,毕竟这是核心指标。
- Support files:代码,脚本等。
这个标准是可以让用户可以按照报告中的描述去复现结果。
有兴趣可以去看Databricks在2021年11月2日提交的最新TPC-DS Report,http://tpc.org/tpcds/results/tpcds_result_detail5.asp?id=121103001。报告需要按照严格的标准来书写,比如运行架构设计,硬件配置,逻辑表设计,存储设计,查询参数和SQL调整,性能指标,硬件软件价格,审核人相关信息,在TPC-DS的说明文档里有很详细的描述,基本可以按照其描述逐一回答各个问题即可。
2021年11月Databricks的这次打榜在100TB数据集上做到了第一,取代了原来阿里EMR的位置。有机会可以看看Databricks底层Photon引擎的一些东西,现在外部能看到的东西还比较少,可能之后也会有论文出来吧。
Reference
- http://tpc.org/tpc_documents_current_versions/pdf/tpc-ds_v3.2.0.pdf
- http://tpc.org/information/about/history5.asp
- https://medium.com/hyrise/a-summary-of-tpc-ds-9fb5e7339a35
- http://www.tpc.org/tpcds/presentations/the_making_of_tpcds.pdf
- https://databricks.com/blog/2021/11/02/databricks-sets-official-data-warehousing-performance-record.html