对于大部分开发人员来说,数据的可靠性,一致性等要求都是逻辑层面上的东西,比如数据库系统中的事务,保证银行里的钱不会出错。但是从存储系统的角度来看,即使我们用各种算法保证了逻辑层面的正确性,真实系统仍然可能因为各种硬件故障导致数据缺失或者出现错误。而静默数据损坏(Silent Data Corruption,记作SDC)是一个很危险的事情,说明这些错误没有通过CPU错误报告机制捕获,无法第一时间显示地被发现,直到应用程序使用数据时才会被发现问题。
对于大公司的infra团队而言,SDC并不罕见,Facebook对这个问题也有一些处理的方法并做了详细的case study,本文简要地做下介绍。
背景
静默数据损坏有些是偶发性的,受到一些射线影响或者环境因素造成位翻转,这些可以用纠错码技术较好地解决。但是有些静默数据损坏是可以复现的,比如CPU计算2x3的结果是5,而不是6。而且随着CPU芯片不断提升的硅密度,架构设计复杂性的不断增加,这个问题需要引起更大的重视。
问题
作为互联网巨头Facebook,发现了不少SDC问题,并对这个问题进行一段时间的监控,给出了一些解决方案缓解数据损坏的风险。
比如在Facebook内部,由Spark支撑的分布式数据查询服务,用户每天会在这个查询服务上运行上百万个ETL任务,其中会计算出被压缩后的文件大小,把计算后的数据压缩存在分布式文件系统之上。但是SDC发生的时候,可能这个计算结果变成了0,结果就是这个文件没有写出去,最终表现就是一个数据集里面缺了部分数据,那么下游数据查询的时候就会发生数据丢失。但显然这样的问题非常难排查。
排查
首先对所有集群机器加上一些日志,最终将范围缩小到一台机器上,在这台机器上可以发现这个问题也是偶发的。最终可以定位到是一个cpu核上对应特定的数据会有可以持续复现的错误。具体到这个case,由于Scala和C/C++不同,它是JIT编译成java字节码跑在JVM上的,不是提前编译好的,就不能拿到机器码指令,需要有一个probe程序可以帮助我们知道实际执行的指令。幸运的是,我们可以加上一个+printAssembly的选项,就可以打印出执行的字节码。
在拿到机器码以后的排查思路,论文给出了一些最佳实践比如绝对地址的引用,外部库调用,编译器优化等。定位到最小的一个代码块,比如在Facebook的这个例子里就是一个scala的math.pow函数。下面是一个排查的工作流。
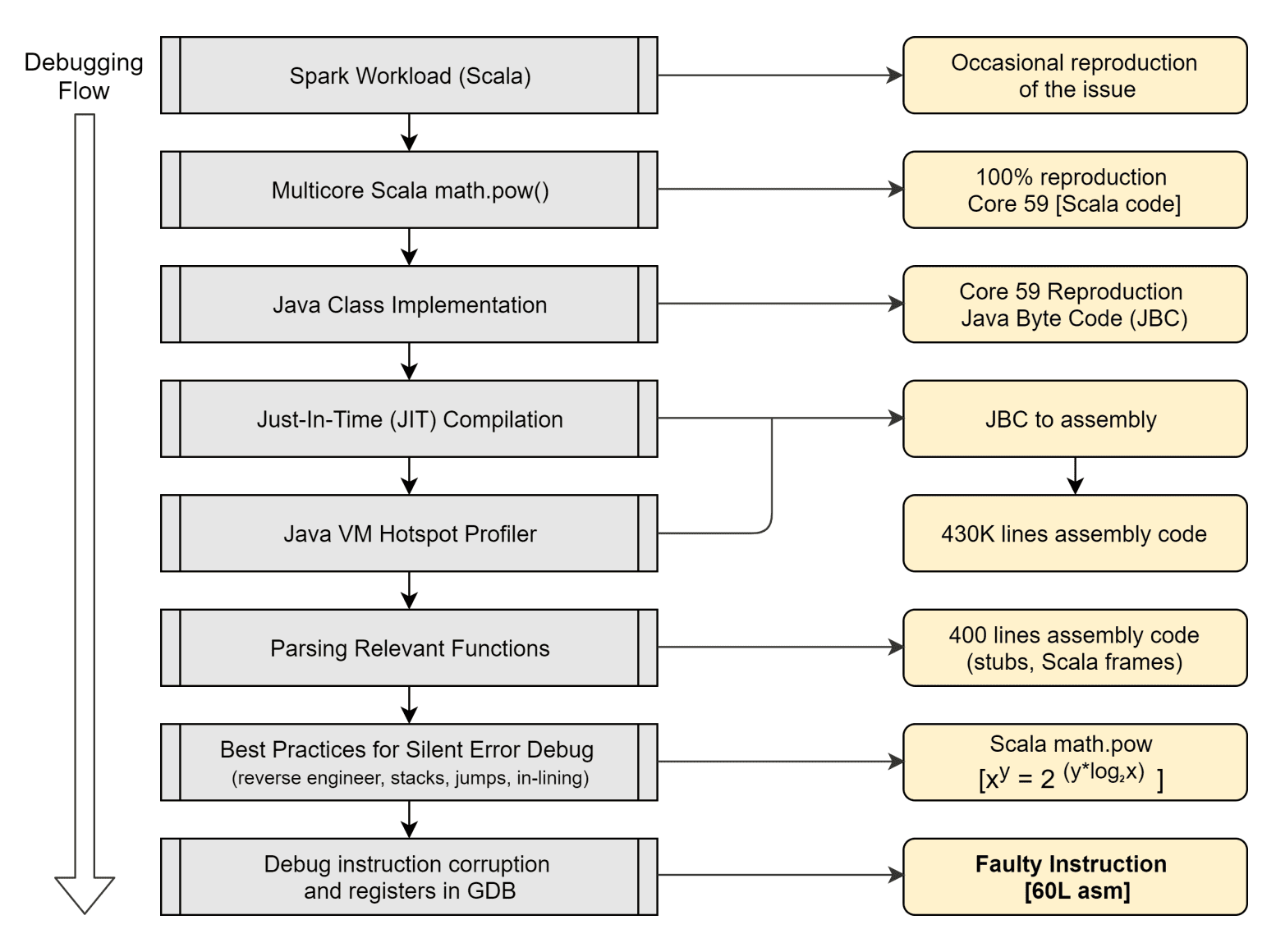
思考
CPU是计算机的大脑,我们总是习惯了CPU是永远不会出错的,但CPU毕竟也是人造出来的工业品,必然会出错。而静默数据损坏确实是一个难以解决的问题,首先定位问题就是一件非常困难的事,平常我们遇到问题的时候必然不会考虑到这个方面,但是对于一个大型的数据中心而言,这出错的机会就大大增加了。似乎没有一个根本解决的方法,毕竟只要是硬件一定会出问题,对于使用方来说建立一个比较完善的监控(面向应用的高效检测),容错机制(快速下线问题机器,在新的机器上重新运行任务)以及问题排查流程(论文里提供的一套方法总结)。