在一篇老文中,简单地梳理了一下ANN的一些发展,也顺便说了自己当时和实验室博士学长一起在做一些研究,论文当时也正在review中,希望等中了能分享下这个工作。但是论文的修改过程也是磕磕绊绊(虽然我没参与太多...),差不多已经过去了两年时间,终于在去年正式被VLDBJ录用了,有兴趣可以去下载,Learning-based query optimization for multi-probe approximate nearest neighbor search,今天就简单地说下这个工作。
分布式查询优化
在一个分布式的向量数据库中,一定涉及到数据的分片,查询请求会下发到每个数据分片,最后把topk结果聚合。有一些工作通过改变数据分片的方式来提升查询性能,比如阿里的ADBV通过Kmeans聚类做数据分片,查询时只访问若干个较近的聚类(数据分片)即可,还有工作通过构造一个小型的图索引,并对这个图索引做图分区,插入数据的时候在这个图索引上找到top1结果,看这个结果所在的图分区即落入对应的数据分片中,查询时用类似的方式找到需要查询的数据分片。
这些方式通过修改数据分片的方式,可以做到pruning的效果,但其实这还是不够的,有了更好的数据分片方法以后,应该搭配上更好的查询算法。从Eearly Termination论文(可见我之前的分享)中我们可以认识到不同查询向量所需要的最优查询参数是不同的,最好的方式为每个查询向量设置query-aware的查询参数。而条件变到分布式查询以后,这时我们需要的query-aware的参数变成了两组,一个是要访问的数据分片列表,另一个每个数据分片上索引的查询参数。为了说明这两个参数的重要性,和Early Termination类似,我们使用实验分析的方式佐证这个motivation足够强,整个论文的可读性也会比较好。
KNN Distribution Function
要做到上述的查询优化,必须要有一个信息指导数据库优化器去做这个决策,并且这个信息需要足够简单。最后我们会发现KDF(KNN Distribution Function)是一个很有用的东西,通过结果数目在不同数据分片内的分布情况,我们会知道哪些数据分片是会被hit到的,并且哪些数据分片是更重要的,如此一来上面的问题都得到了解决。而准确KDF的获取显然是找到查询结果才能回答的,这就会出现一个鸡生蛋和蛋生鸡的问题,但是我们可以用机器学习的方式去预测一个相对比较准确的KDF即可,并且这个机器学习问题是一个比较well-defined的问题,我们可以直接用很多经典的模型去套用。最后整体workflow如下图所示
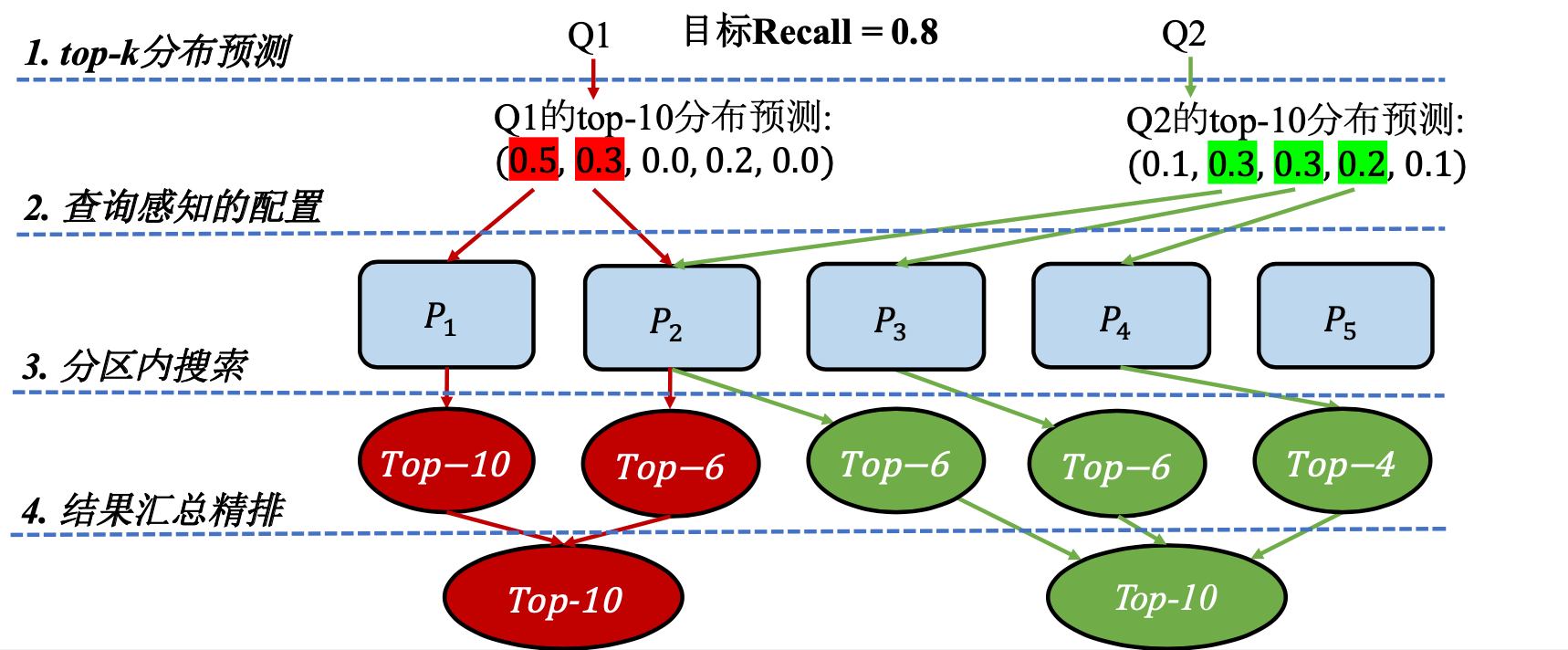
实验结果
论文中使用Kmeans聚类做数据分片,在每个数据分片上构建HNSW图索引,使用前面提到的方法,在上亿数据集上实现了3-4倍的性能。当然其实论文这里可以补充的一个对比是数据做随机分片下的结果。另外由于模型是很轻量的,使用推理框架带来的开销相对查询开销可以忽略。
思考
从个人角度来看,这个方法整体思路足够简单,但实际使用仍然有很多需要考虑的点。
- 对于Kmeans聚类,不同数据分片的数据量是很不均匀的,而这个会导致workload的不均衡,给系统load balance增加难度。
- 模型的使用对于数据库系统肯定是一个不小的心智负担,需要额外增加训练和model serving的事情,AI for DB很火,但是真正能用上的机会很少。
- 数据的增删改会成为问题,可以使用lambda架构的方式去做增量数据和存量数据的维护,但是数据的repartition这个开销还是比较大的,这意味着增量数据积累到一定程度dump成为存量数据以后,可能存量数据会分为聚类的数据和非聚类的数据。
- 查询参数的设置仍然是一个复杂的问题,虽然KDF揭示了不同数据分片之间的重要程度,相关性(相对比例)是知道了,但是无法确定大家的绝对数值。如果用户希望的recall是一个确定数值,系统仍然无法直接给出查询参数推荐,需要一定的调参过程,而这个预处理过程现在仍然是由用户承担的。并且常见的图索引其实可调的查询参数只有一个,如果使用一些查询参数更多的索引,这会让调参的难度更高。